Measured product lead custody receipt.
github.com/Zer0pa/Energy-Physics-PipelineRESEARCH-READY
LIVE
H100 WAVE OPEN
Six-Layer Physics Energy R&D
In-silico physics pipeline · electrochemistry to fusion · Energy-Physics-Pipeline
Energy research groups need a reproducible baseline before they spend H100 budget.
Energy-Physics-Pipeline organizes six in-silico layers — electrons, atoms, mesoscale, device, stack, orchestration — across electrochemistry and fusion/plasma research, all running on commodity CPUs today. 475 of 475 strict CPU tests pass at 79.72% coverage; 39 of 39 source manifests verify; 6 of 6 anchors resolve. H100 execution remains untested. This is research infrastructure, not a deployable energy product.
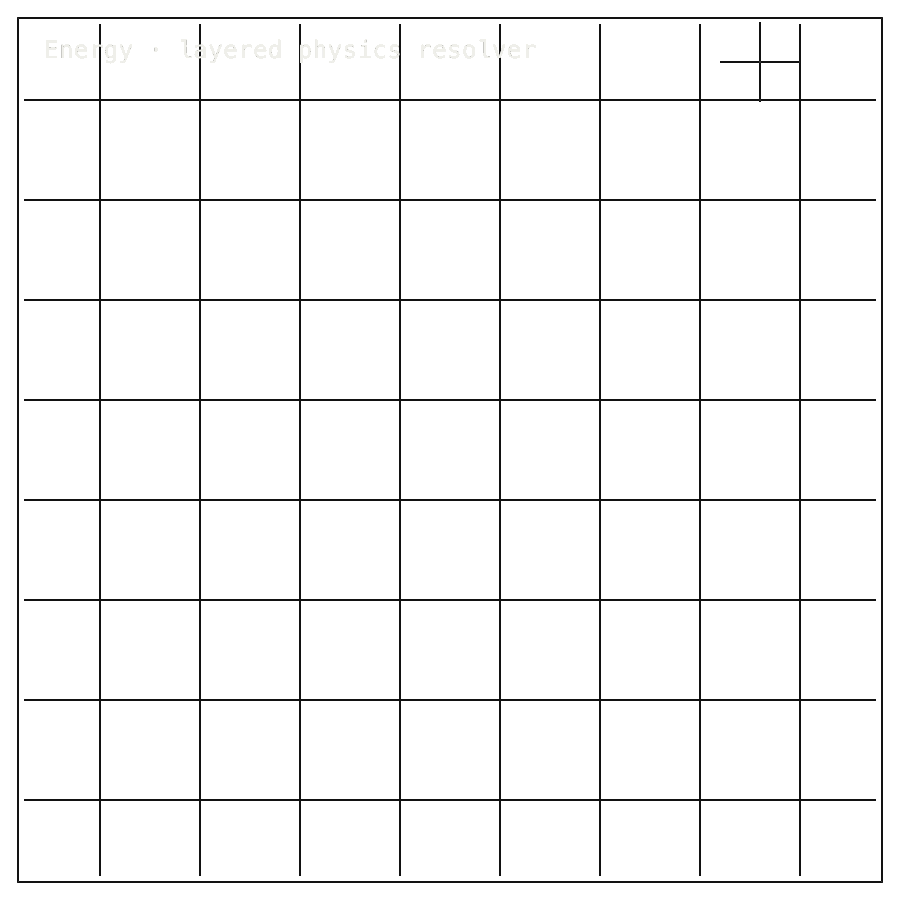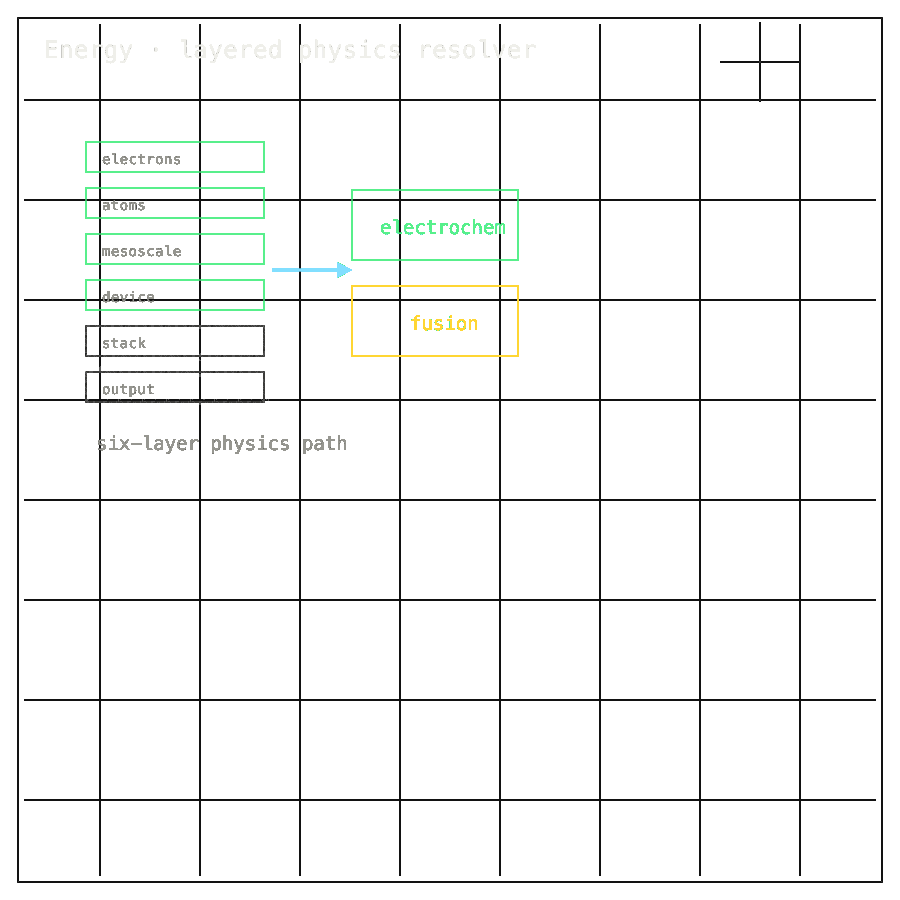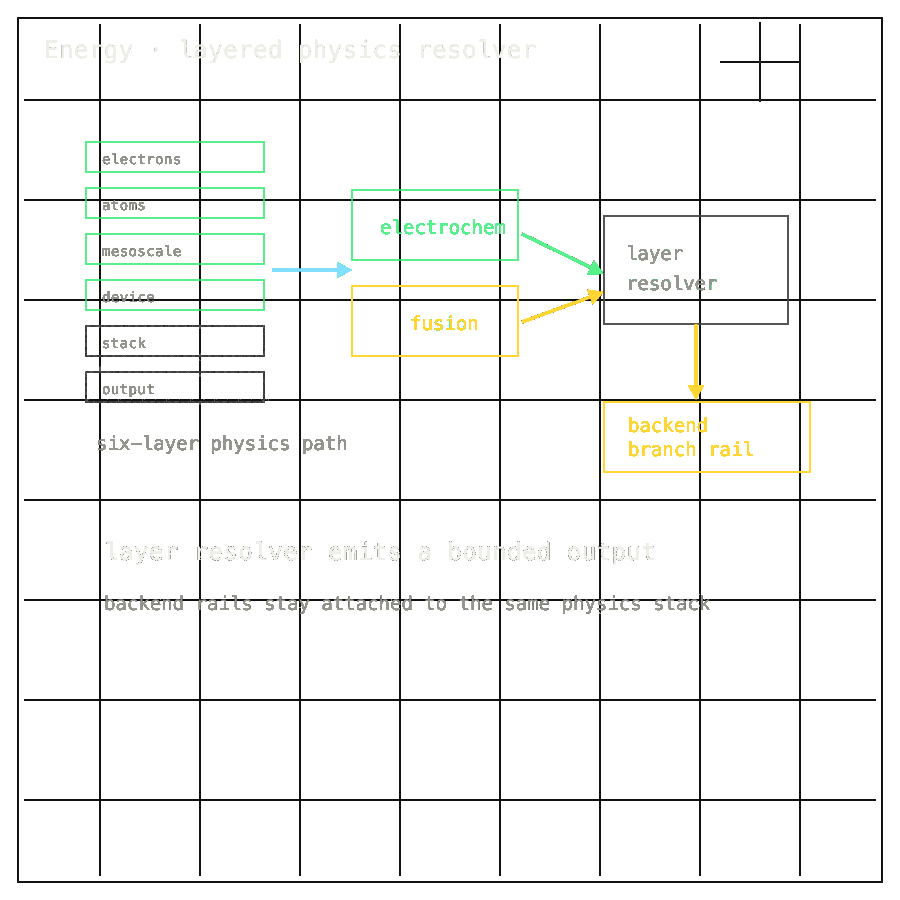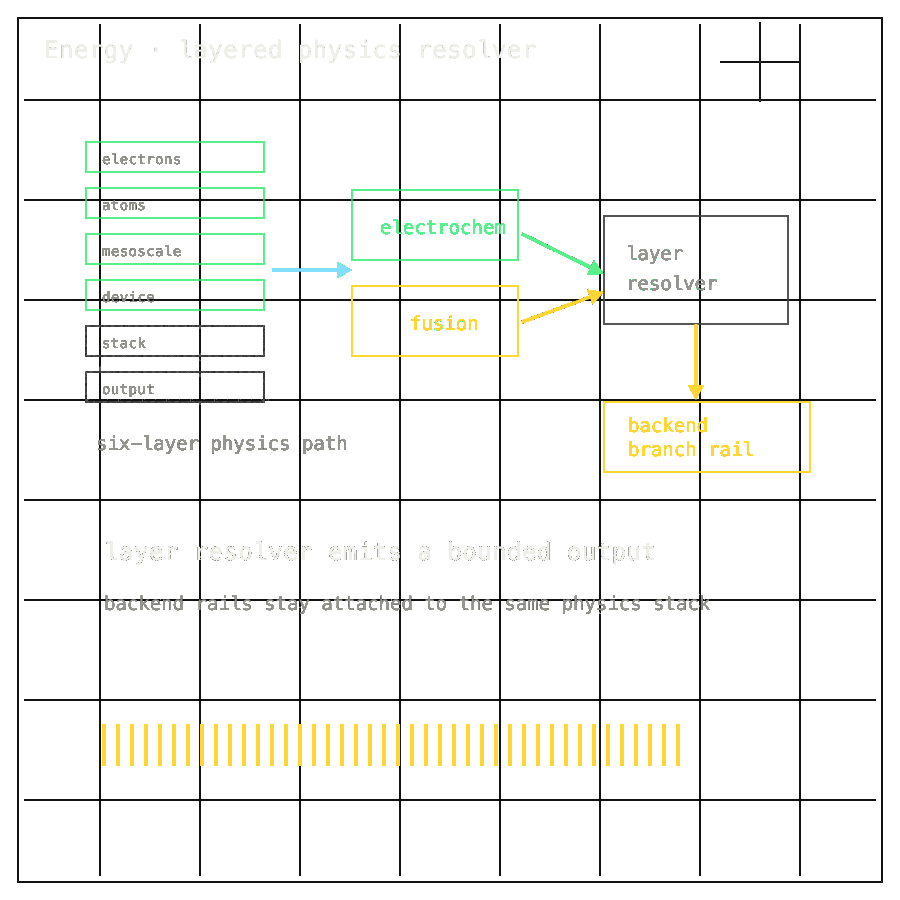
01 · THE GAPCPU BASELINE FIRST
“Energy teams need a reproducible CPU baseline. physics runs carry weight after evidence.”
02 · MARKETSUSER GROUPS
Adjacent energy-transition forecasts; this pipeline is research infrastructure, not a deployable energy product or certification claim.
03 · VALUE
475/475PASS
Six layers run end-to-end on commodity CPUs, before any GPU hour is spent.
04 · INSIGHT
475 / 475 CPU pass; GPU execution still untested.
05.0 · CURRENT TECHPOINT TOOLS + HPC
Battery, electrochemistry, and fusion teams each run mature solvers — but in separate stacks, with separate manifests, separate result formats, and separate notions of which version of which dataset was actually used.
05.1 · OUR TECHCPU-FIRST BASELINE
Energy-Physics-Pipeline ships one CPU-first stack across six layers — electrons, atoms, mesoscale, device, stack, orchestration. Source manifests resolve at known SHAs, electrochemistry and fusion runs share the same execution path, and the same code path will run on GPU once cluster time arrives. A research engineer can re-run the full chain on a laptop.
05.2 · BENCHMARKSSTRICT FULL CHECK
Strict475 / 475tests PASS
Coverage79.72% of source
Sources39 / 39verified, 0 miss
Anchors6 / 6resolve
Open work: H100 enterprise wave untested — 180–500 GPU-hours pending real cluster time.
06 · MEASUREMENTSTRICT FULL + SOURCE VERIFY
CPU results come first; GPU runs are still untested.
06.1 · BOUNDED VALIDATION ON STRICT CPU CHAIN
Strict CPU check plus source verification across all six layers · 39 of 39 manifests resolve at known SHAs · GPU execution path wired but unrun · H100 wave open at 180–500 GPU-hours.
07 · KEY METRICSSTRICT FULL CHECK + SOURCE VERIFY
07.1 · CPU STRICT CHECK
475/475PASS
Strict full check · 0 miss
07.2 · COVERAGE
79.72%
Of source · strict full check
07.3 · SOURCE MANIFESTS
39/39OK
Verified at known SHAs · 0 miss
07.4 · H100 BUDGET
180–500HRS
H100 execution · not yet run
07.5 · PIPELINE LAYERS
6layers
Electrons through orchestration
08 · DETERMINISMFROZEN-INPUTS · CPU CHAIN
CPU layer outputs re-derive from frozen inputs.
08.1 · WHAT DETERMINISTIC MEANSSTRICT-FULL · SAME ENDPOINTS
Across all six layers — electrons through orchestration — current results are reproducible from frozen inputs on commodity CPU. Source manifests resolve at known SHAs, and Runpod cutover hooks preserve the same endpoint shape for later GPU runs.
Unit of bit-exactness: per-layer, against strict-full on a fresh venv. H100 enterprise work must later pass CPU-vs-GPU regression against real GPU artifacts before it can claim parity with the CPU baseline.
08.2 · THE FIDELITY GAP
Honest Blocker ·
No GPU-backed enterprise completion wave has run yet. PyPI remains at energy-physics-pipeline 0.1.0 with stale text; 0.1.1 is pending. Smoke tests and shaped envelopes are not completion. No production, regulatory, or defense claim. 180–500 H100-hours are owed before this becomes a GPU-backed result.
09
One stack from electrons to fusion.
09.1 · THIS REPO'S AMBITION
The ambition is one public energy-computation workbench that a fusion lab, an electrochemistry group, and a grid-physics modeler can all extend without forking. CPU baselines, GPU execution, source manifests, and domain routing share one architecture so the science argument stays about physics, not tooling.
09.2 · WHAT WORKS NOW
Working now: CPU strict baseline, source manifests at known SHAs, domain routing; Runpod GPU cutover staged.
09.3 · WHAT'S STILL OPEN
Still open: H100 execution wave, PyPI 0.1.1 release; GPU-comparison artifacts and broader domain data.
09.4 · RELEASES · NEAR-TERM (12–24 MO)
Public package matches the working repo
A research engineer evaluating tools no longer has to choose between a stale PyPI page and a fresher GitHub. Procurement, software audits, and library-of-record decisions can use the same identity the running pipeline carries.
09.5 · ELECTROCHEMISTRY · NEAR-TERM (12–24 MO)
Battery and hydrogen runs gain a shared yardstick
A battery-materials group and a hydrogen-electrolyzer group can compare numbers across the same six-layer chain instead of arguing about toolchains. CPU baselines settle the methodology argument before either team spends device-cluster hours.
09.6 · FUSION · MID-TERM (24–48 MO)
GPU plasma runs inherit the CPU receipt
When H100 fusion and plasma work lands inside the same execution path, scale stops weakening evidence. A national lab can attach the GPU run, the CPU comparison, and the source manifest to the same record a reviewer will read.
09.7 · DOMAINS · MID-TERM (24–48 MO)
Energy domains stop forking their stacks
Battery research, fuel-cell modeling, and fusion teams stop maintaining bespoke pipelines for queueing, source manifests, and result tables. A shared workbench means a postdoc moves between domains without learning a new operations stack.
09.8 · GRID · PARADIGM (48 MO+)
Energy R&D ships the whole run,not the result
Funders, regulators, and grid planners stop reviewing a single number. They review the run object — inputs, environment, source SHAs, comparisons, boundary notes — and decide what to fund or interconnect against an artifact they can re-run themselves.